

SPR{K3 Security Research · May 2026
—
AI infrastructure is a specific target. Model serving layers, training pipelines, LLM gateways, agent orchestration frameworks, vector stores, RAG pipelines — these are not generic software. They have their own attack surfaces, their own trust boundary failures, and their own class of vulnerabilities that general-purpose security tooling was never designed to find.
The market response so far has produced runtime guardrails for LLM applications, model file scanners for supply chain integrity, behavioral red teaming platforms, and most recently, AI-reasoning SAST replacements from Anthropic and OpenAI. Each of these solves a real problem.
None of them scan the source code that actually runs your AI infrastructure for the vulnerabilities that have been quietly producing CVEs at NVIDIA, Meta, Microsoft, Google, and Amazon for the past three years.
That is the layer Defend covers.
—
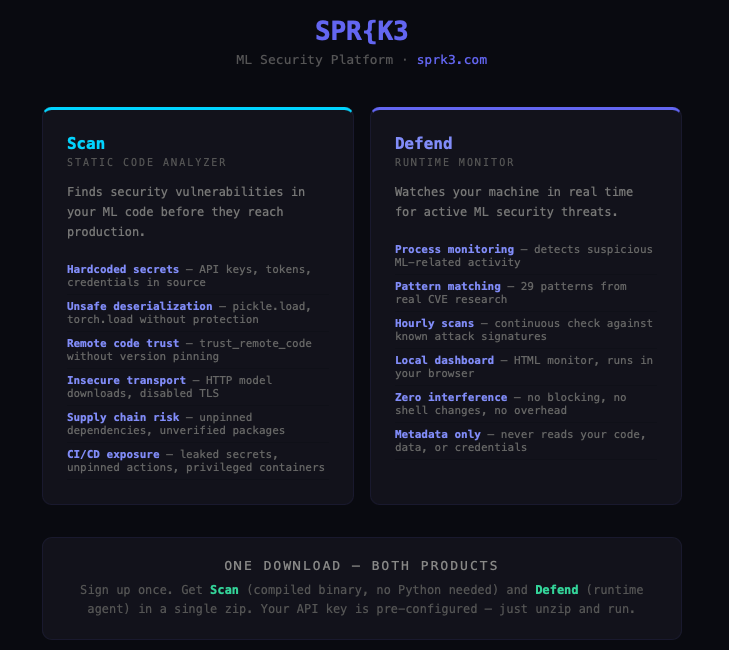
What Defend Is
Defend is a security agent for AI infrastructure. It ships two capabilities in a single installation: runtime monitoring and static code analysis.
The static engine runs locally on your endpoint, against your codebase, on a schedule you control. It carries patterns derived from SPR{K3’s continuous vulnerability research — patterns that exist because we found the underlying vulnerabilities first and walked them through coordinated disclosure with the vendors whose software you are running.
The runtime layer watches process execution in real time. When a process attempts an unsafe deserialization on live data, when a subprocess chain matches a known exploit pattern, when an inter-agent communication crosses a trust boundary it shouldn’t, Defend fires before the operation completes.
Both layers ship as a compiled native binary — no Python, no dependencies. macOS ARM64, Windows x64, Linux ELF. One signup, one download, auto-detects OS.
When the static scanner finds something, the server receives a finding record: severity, pattern ID, line number, and a SHA256 hash of the file path. The server never sees `/home/engineer/projects/inference_pipeline/model_loader.py`. It sees `a3f8b2c1e9d04f71`. It knows you have a critical deserialization sink. It has no idea where.
Detection happens on your hardware. The intellectual property stays on your hardware.
—
What Defend Is Not Replaced By
Buyers evaluating AI infrastructure security will encounter several established categories first. Each of them solves a real problem. None of them solves the problem Defend solves.
AI-Reasoning Code Scanners
In February 2026, Anthropic launched Claude Code Security, powered by Claude Opus 4.7. OpenAI followed with Codex Security shortly after. Both are general-purpose static code analyzers driven by frontier reasoning models — they read code, trace data flows, and reason about vulnerabilities the way a human researcher would, rather than matching against rule sets. Both are effectively free to existing enterprise customers of those AI labs.
For organizations replacing legacy rule-based SAST tools across a general application portfolio, these will likely produce better results than what they replace. The category is commoditizing.
For AI infrastructure specifically, three structural limits matter.
First, they are generalists. A frontier reasoning model can identify that a `pickle.loads()` call is risky. It cannot necessarily distinguish between a `pickle.loads()` in a test fixture, one wrapped in a defensive validation pattern, and one sitting at the end of a multi-step taint chain through a model conversion script that nobody catches in code review. Defend’s patterns exist because we filed those exact distinctions as CVEs.
Second, they are probabilistic. AI models are probabilistic by nature — the same code, scanned twice, can produce different findings. For coordinated disclosure that is fine; a researcher uses judgment regardless. For an enterprise security program with audit requirements and reproducible compliance attestations, probabilism is a structural problem. Defend’s static engine is deterministic. Same code, same patterns, same findings, every time.
Third, they run in the cloud. Your source code reaches Anthropic’s or OpenAI’s servers to be scanned. For organizations whose AI infrastructure code is differentiated IP, that is a different conversation than scanning generic application code.
Model and Supply Chain Scanners
HiddenLayer Model Scanner and Palo Alto Prisma AIRS (which absorbed Protect AI’s Guardian product line through Palo Alto’s 2025 acquisition) are the established AI security pure-plays. HiddenLayer scans model files — pickle, ONNX, safetensors, GGUF — for embedded malware, backdoored weights, malicious serialization payloads, and supply chain tampering. Prisma AIRS bundles model scanning with AI Security Posture Management for inventory and shadow AI discovery, plus runtime enforcement at the network layer.
These are mature. HiddenLayer integrates with Microsoft Azure AI, Databricks Unity Catalog, and AWS marketplace. Prisma AIRS sits inside the broader Palo Alto enterprise stack. For organizations operating large model repositories, they solve real problems.
They solve a different problem than Defend.
HiddenLayer scans the artifact: the `.pt` file, the `.onnx` file, the model registered in your catalog. Prisma AIRS governs the runtime environment: which agents can access what, where workloads run, how AI traffic flows. Defend scans the code that loads, converts, serves, and orchestrates models — the Python, Go, and C++ that surrounds your model files.
A perfectly clean model file is still exploitable when the code that loads it calls `torch.load()` without `weights_only=True` on user-supplied input. A scanned-clean `.onnx` file does nothing to protect a conversion pipeline that pickles arbitrary Python objects from a network socket. Runtime governance at the network layer does not see a deserialization sink in your model serving code.
That is the layer where the most exploitable AI infrastructure vulnerabilities actually sit, and where Defend’s patterns come from.
Runtime Guardrails and Red Teaming
Lakera (acquired by Check Point in November 2025 for $300M), Aim Security, Prompt Security, Lasso Security, CalypsoAI, and the open-source equivalents (LLM Guard, NeMo Guardrails, Garak, Promptfoo) sit between user input and the model. They block prompt injection, filter sensitive data leakage, and enforce output policy at inference time.
Mindgard, Robust Intelligence (acquired by Cisco in 2024), Repello AI, and Adversa AI run simulated adversarial attacks against deployed models to find behavioral weaknesses.
These are not competitive with Defend; they are complementary. Defend does not do prompt injection guardrailing or model red teaming. Lakera does not find unsafe deserialization in your model loading pipeline. The categories address different layers of the same problem.
—
What Defend Catches That Others Don’t
Deserialization chains. A `pickle.loads()` call is dangerous not because the call exists, but because of where the data came from. Defend traces taint from user-controlled sources through network boundaries and trust context changes to the sink — flagging the paths that are exploitable, not just the ones that are present. This is cross-file analysis on real codebases, not pattern matching.
Inter-agent trust failures. As AI systems become agentic — LLMs calling tools, agents spawning subagents, orchestrators delegating to workers — the trust boundaries between components become the attack surface. Defend covers these inter-agent communication patterns specifically.
RAG and vector store poisoning. Retrieval-augmented systems introduce new ingestion surfaces. Defend detects vector store writes without provenance validation, metadata ranking manipulation at retrieval boundaries, and dataset versioning rollbacks without audit trail.
LLM gateway credential exposure. Proxy layers sitting between applications and model providers hold API keys and provider credentials. Defend covers the injection surfaces that allow unauthenticated extraction of those credentials — the class of vulnerability that turns one SQL injection into compromise of every downstream model provider.
Compound chains. The most dangerous AI infrastructure vulnerabilities are not individual issues. They are chains. A SQL injection in an LLM gateway extracts API keys. Those keys reach a model serving layer with an unsafe deserialization sink. The container runs on a shared-kernel host. One compromised prompt becomes root on the host. Each step in isolation is medium severity. Together they are a critical escalation path. Defend’s cross-fire escalation rules surface the compound risk, not the individual components.
“By design” risk. A significant portion of AI infrastructure vulnerabilities are closed by vendors as expected behavior — architecturally dangerous defaults shipped without safeguards because no individual component is technically broken. These findings never reach CVE databases. They never appear in public advisories. They are not in the training data of any reasoning LLM, and they do not show up in threat intelligence feeds that aggregate from published disclosures. The risk they represent does not go away because the vendor declined to patch. Defend detects them because we filed the disclosures and built the patterns from the vendor responses, including the rejections.
—
The Layered View
Model file scanning, runtime governance, inference-layer guardrails, behavioral red teaming, and source code security for AI infrastructure are five different layers of the same problem. A mature AI security program covers more than one.
For most organizations the right answer is several tools, each in their layer. HiddenLayer or Prisma AIRS for model artifact integrity. Lakera or an equivalent for inference-layer guardrails. Mindgard or similar for behavioral red teaming. Claude Code Security or Codex Security for general application code.
Defend covers the layer none of those reach: the actual source code that runs your AI infrastructure, scanned with patterns that exist because we found the underlying vulnerabilities first, executed locally so your code never leaves your environment, and shipped with runtime exploit detection at the infrastructure layer rather than the inference boundary.
For organizations protecting AI infrastructure where the source code is sensitive IP, where compliance requires reproducible findings, where the threat model includes vulnerabilities that have not yet been publicly disclosed, and where runtime protection is needed beyond inference-layer guardrails — that is the gap Defend fills.
The conversation starts at [support@sprk3.com](mailto:support@sprk3.com).
—
SPR{K3 Security Research. Confirmed CVEs and findings across NVIDIA, Meta, Microsoft, Google, and Amazon.
[defend.sprk3.com](https://defend.sprk3.com) · [sprk3.com](https://sprk3.com)
